
[Database] 트랜잭션과 인덱스
Transaction
⭐ Transaction이란?
transaction는 데이터베이스 내에서 수행되는 작업의 최소 단위로, 데이터베이스의 무결성을 유지하며 DB의 상태를 변화시키는 기능을 수행 transaction은 하나 이상의 query를 포함해야 하고, ACID라고 칭해지는 원자성, 일관성, 고립성, 지속성의 4가지 규칙을 만족해야 한다.
Transaction 예시
은행 시스템에서 A가 100만원을 출금해서 B에게 입금하는 상황을 생각해보자. A의 잔고에서 100만원을 출금하였는데, 이 때 전산오류가 생겨서 B의 계좌에는 100만원이 입금 되지 않았다. 이런 상황은 전산시스템의 치명적인 오류!
이렇게 예상치 못하게 오류가 발생하여 하여 데이터의 부정합이 발생하는 경우, 다시 원상복귀 해야한다. 따라서 모든 입출금은 하나의 묶음 형태로 작동해야 한다. 출금을 했으면 입금을 마치던지 아니면 아예 없던 일이 되어야 한다. 이런 식으로 두 행위는 분리될 수 없는 하나의 거래로 처리돼야 하는 단일 업무!
이러한 업무 처리의 최소 단위를 데이터베이스에서는 transaction이라 함
데이터베이스에서 Transaction이 필요한 이유는 데이터를 다룰 때 장애가 일어나는 경우, transaction은 장애 발생시 데이터를 복구하는 작업의 단위가 되기 때문! 또한 데이터베이스에서 여러 작업이 동시에 같은 데이터를 다룰 때가 있다.
transaction을 통해 이 작업을 서로 분리하고, 이를 통해 오류가 발생하지 않게 해야 한다. DBMS는 transaction이 이러한 규칙을 유지하도록 지원
START TRANSACTION
// (1) A 계좌 잔액 가져옴 A = 1000
// (2) B 계좌 잔액 가져옴 B = 1000
// (3) A 출금 A = A - 100
// (4) B 입금 B = B + 100
UPDATE Customer SET balance = balance - 100 WHERE name='A';
UPDATE Customer SET balance = balance + 100 WHERE name='B';
//COMMIT
// (5) A 계좌 잔액 저장 A = 900
// (6) B 계좌 잔액 저장 B = 1100
COMMIT
ACID
트랜잭션은 데이터베이스의 무결성을 유지하기 위해 원자성, 일관성, 고립성, 지속성의 성질을 갖는다
- Atomicity(원자성) : transaction에 포함된 작업은 전부 수행되거나 아니면 전부 수행되지 말아야 한다.(all or nothing)
- Consistency(일관성): transaction이 실행을 성공적으로 완료하면 언제나 일관성 있는 데이터베이스 상태로 유지하는 것을 의미한다. 송금 전후 모두 잔액의 data type은 integer이여야 한다는 것이 일관성의 한 예가 될 수 있다.
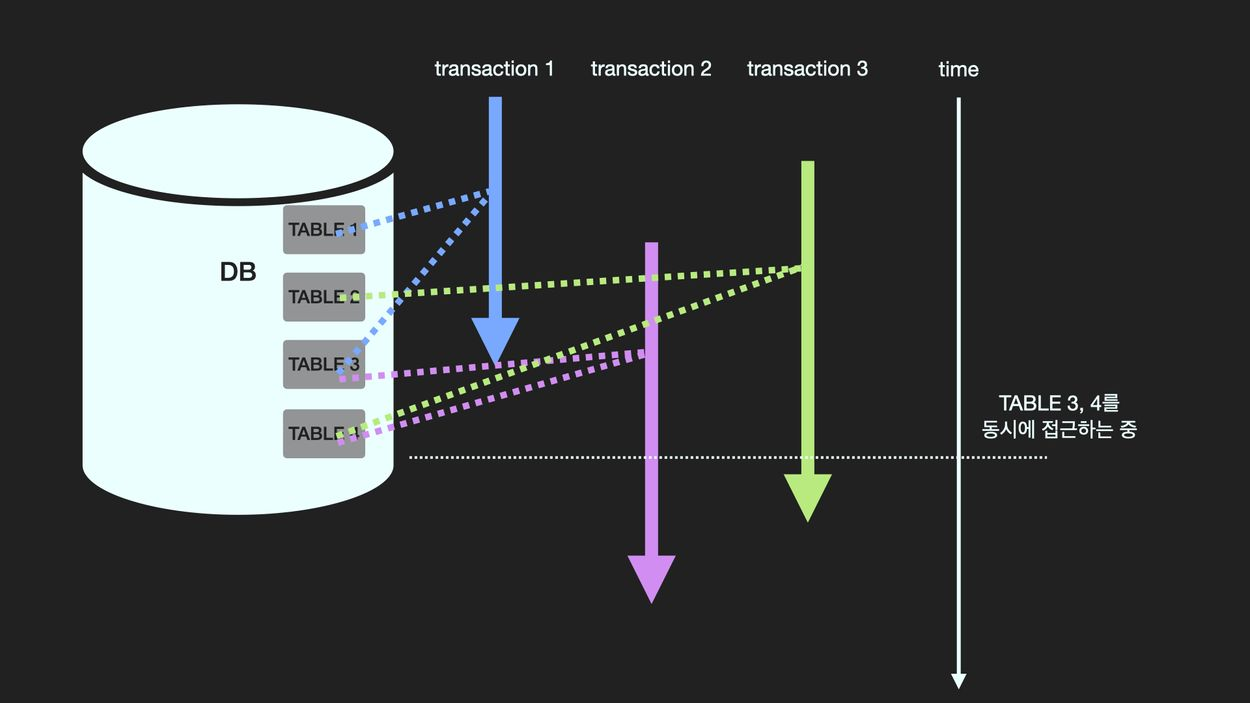
- Isolation(고립성): 여러 Transaction은 동시에 수행. 이때 각 transaction은 다른 transaction의 연산 작업이 끼어들지 못하도록 보장하여 독립적으로 작업을 수행. 따라서 동시에 수행되는 transaction이 동일한 data를 가지고 충돌하지 않도록 제어해줘야 한다. 이를 동시성제어(concurrency control)
- Durability(지속성): 성공적으로 수행된 transaction은 데이터베이스에 영원히 반영되어야 함을 의미. transaction이 완료되어 저장이 된 데이터베이스는 저장 후에 생기는 정전, 장애, 오류 등에 영향을 받지 않아야 한다.
동시성 제어(concurrency control)
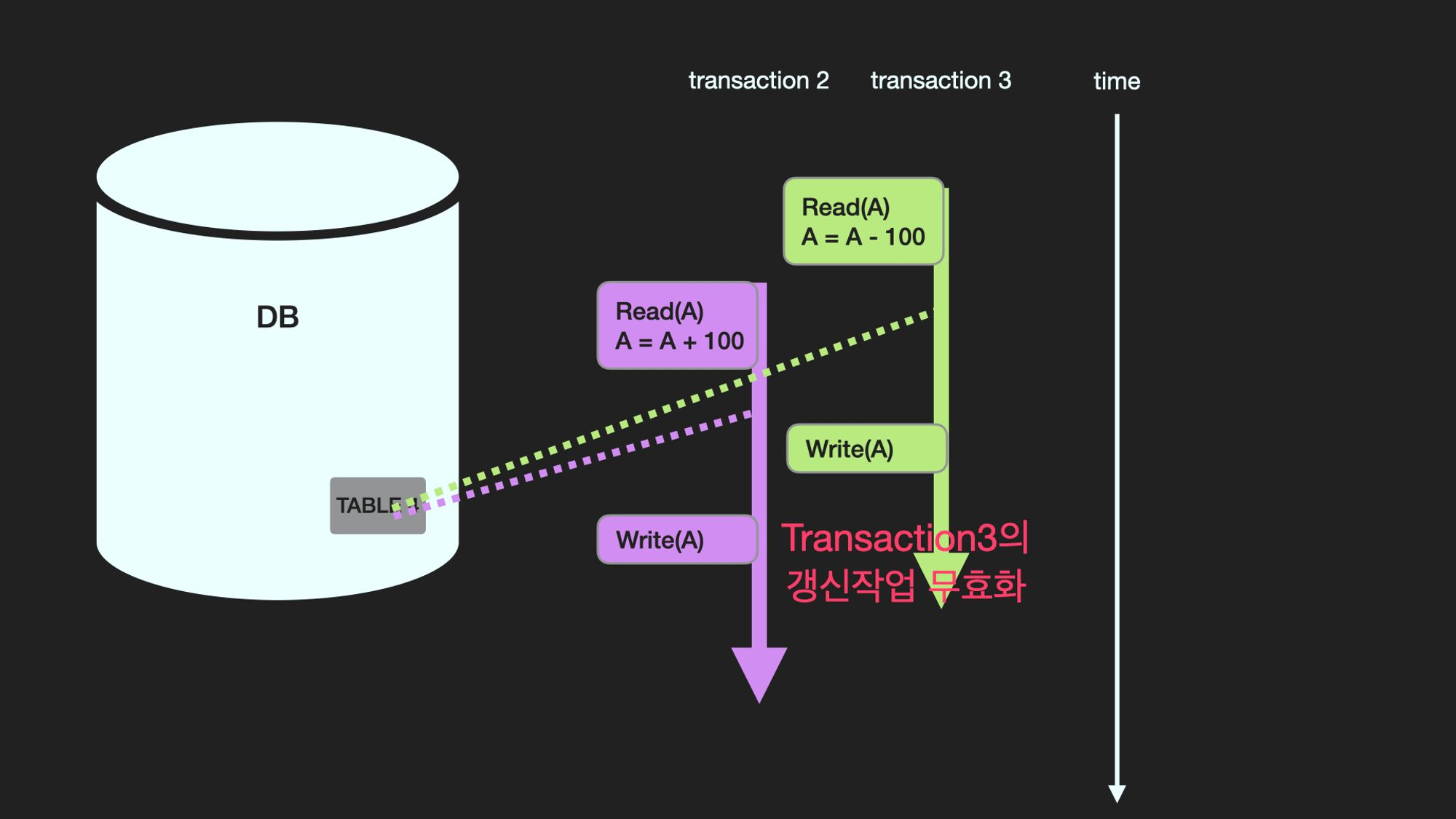
여러 개의 transaction이 한 개의 데이터를 동시에 갱신(update)할 때 어느 한 transaction의 갱신이 무효화 될 수 있는데 이를 갱신손실이라고 함. 동시성제어를 통해 갱신손실을 미리 막을 수 있다. 즉, transaction이 동시에 수행될 때 일관성을 해치지 않도록 transaction의 데이터 접근을 제어하는 DBMS의 기능을 동시성제어라고 한다.
갱신손실 문제를 해결하기 위한 방법중에 하나로 데이터를 수정중에 있는 transaction은 해당 데이터를 Lock으로 잠금장치를 하여 다른 Transaction이 접근하지 못하게 하는 방법이 있다. Lock이 걸린 데이터는 Unlock이 될 때까지 다른 Transaction들은 접근하지 못하고 기다려야 한다.
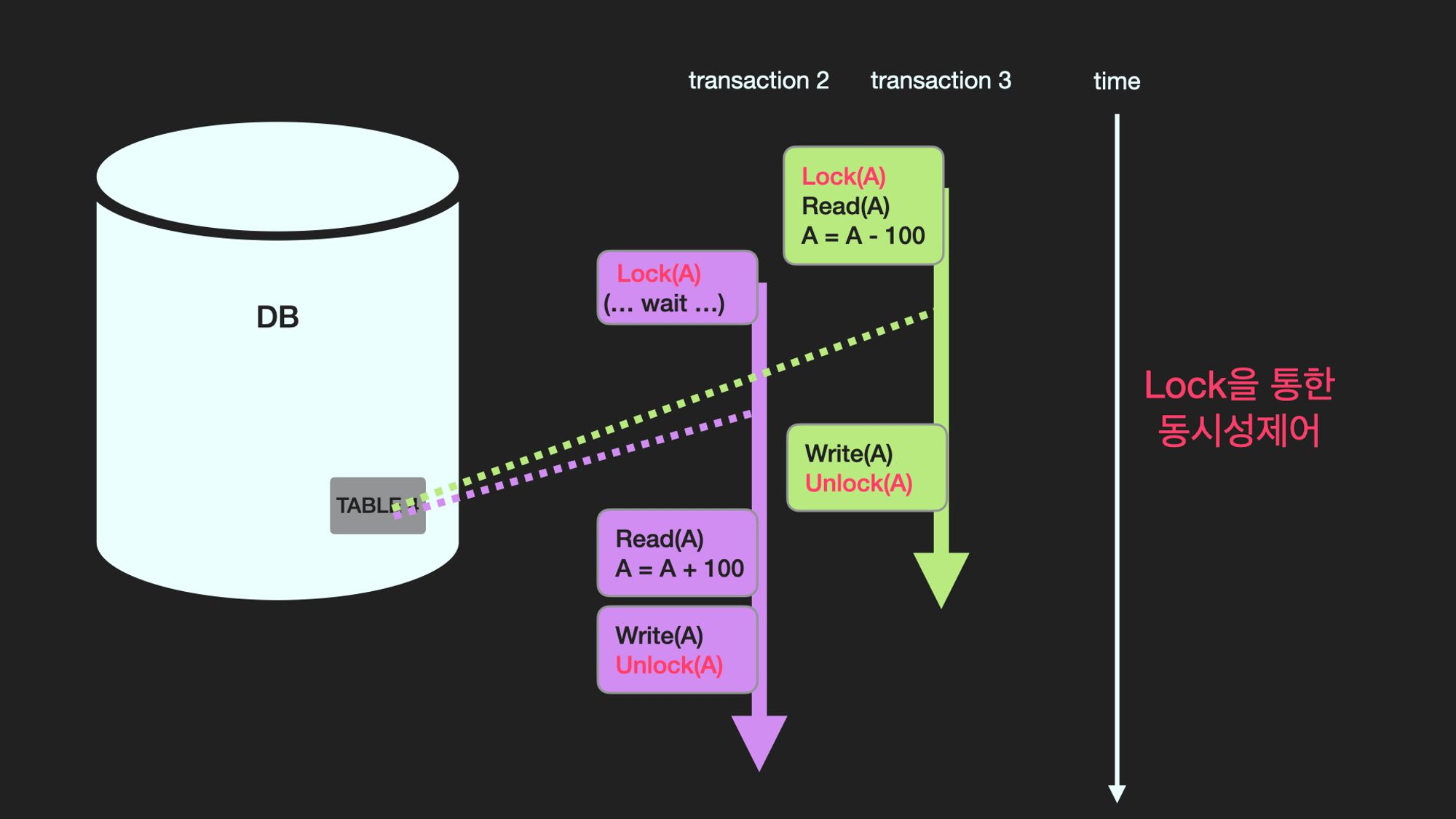
⭐ DeadLock이란?
데이터베이스 deadlock(교착 상태)이란, 여러 transaction들이 각각 자신의 데이터에 대하여 lock을 획득한 상태에서 상대방 데이터에 대하여 접근하고자 대기를 할 때 교차 대기를 하게 되면서 서로 영원히 기다리는 상태
Deadlock
두 transaction이 각각 lock을 설정하고, unlock을 하지 않은 상태에서 서로의 lock이 걸린 데이터에 접근하려고 할 때, 서로 대기를 계속하여 영원히 처리되지 않는 상황
- ⭐ deadlock을 해결하는 방법
- 예방기법: 각 transaction이 실행되기 전에 필요한 데이터를 모두 Locking 해주는 것. 하지만 locking해줘야 하는 데이터가 많다면 사실상 모든 데이터를 전부 locking한 것과 동일하여 transaction의 병행성을 보장하지 못할 수 있다.
- 회피기법: 자원을 할당할 때 timestamp를 사용하여 deadlock가 일어나지 않도록 회피하는 방법.
- 탐지/회복 기법: Transaction이 실행되기 전에는 아무런 검사를 하지 않고, deadlock이 발생하면 이를 감지하고 회복시키는 방법.
Index
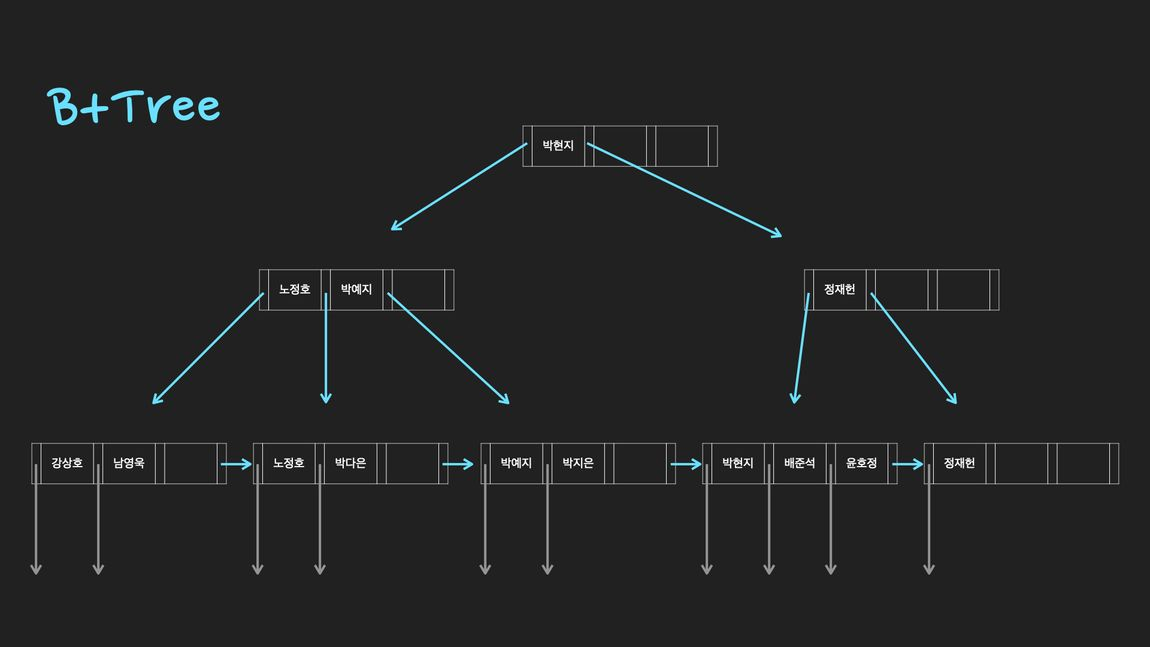
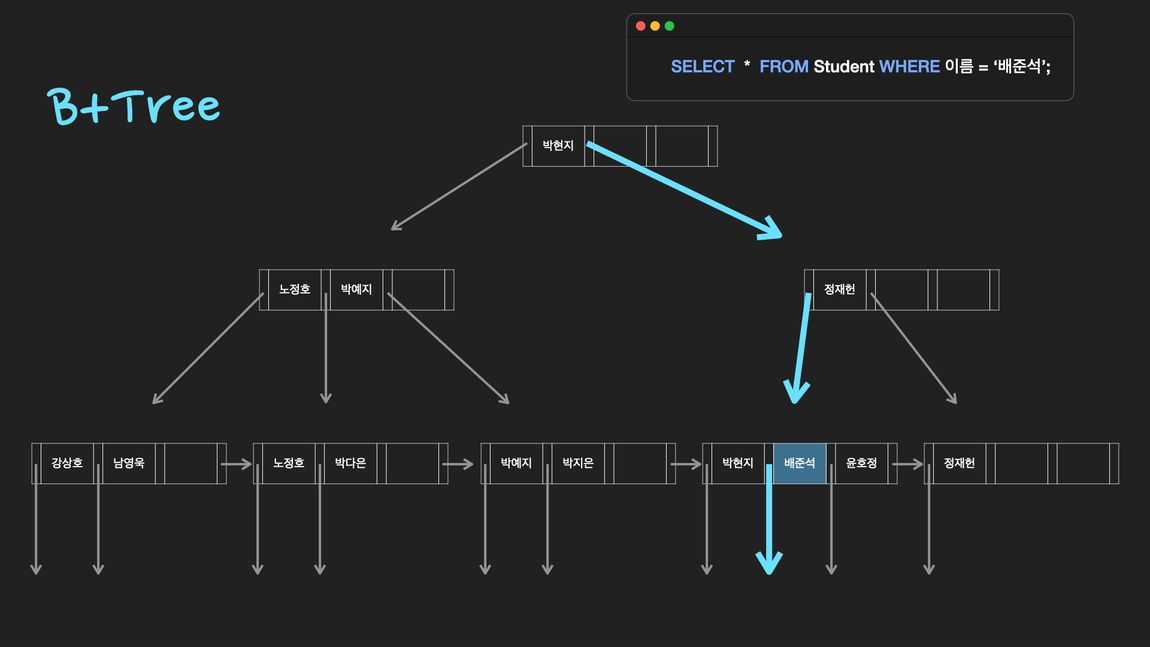
Index는 데이터베이스에서 table의 검색 성능을 높여주는 대표적인 방법중 하나. 일반적인 RDBMS(관계형데이터베이스)에서는 B+Tree구조로 된 index를 사용하여 검색속도를 향상시킨다.
index는 책마다 마지막 페이지에 있는 색인(index)과 같은 역할을 하는 자료구조. 책에서 어떤 용어나 단어를 찾기위해 첫 페이지부터 끝 페이지 까지 전체를 훑지 않아도(Full Table Scan) index를 찾아보면 몇 페이지에 적혀 있는지 바로 찾을 수 있는 것(Index Scan)과 비슷하다.
SELECT ~WHERE query를 통해 특정 조건을 만족하는 데이터를 찾을 때, full table scan할 필요 없이 정렬되어 있는 index에서 훨씬 빠른 속도로 검색을 할 수 있게 된다.
Index 구조
- Index는 Btree, B+tree, Hash, Bitmap로 구현될 수 있습니다. 많은 데이터베이스 시스템에서 index는 B+tree구조.
- index를 생성하게 되면 특정 column(속성, attribute)의 값을 기준으로 정렬하여 데이터의 물리적 위치와 함께 별도 파일에 저장.
- 이 때, Index에 저장되는 속성 값을 search-key값이라고 하고 실제 데이터의 물리적 위치를 저장한 값을 pointer라고 함
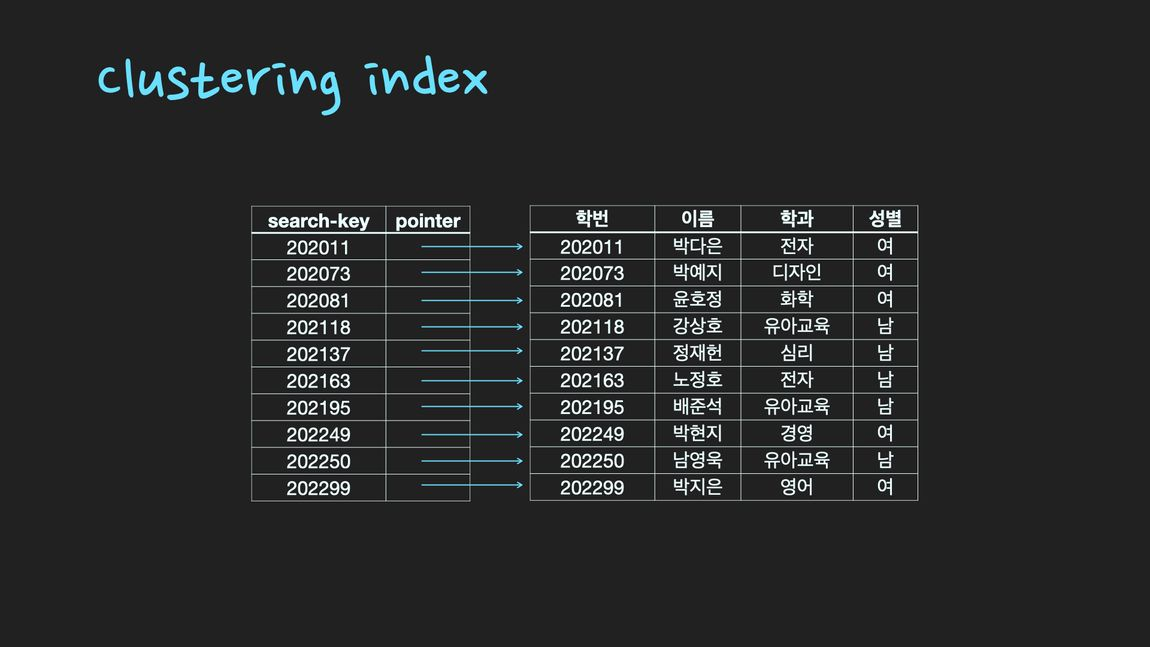
- 즉, index는 순서대로 정렬된 search-key값과 pointer값만 저장하기 때문에 table보다 적은 공간을 차지
정리해보면 특정 column을 search-key 값으로 설정하여 index를 생성하면, 해당 search-key 값을 기준으로 정렬하여 (search-key, pointer)를 별도 파일에 저장하고, 이를 index라고 한다.
Index 사용하는 이유
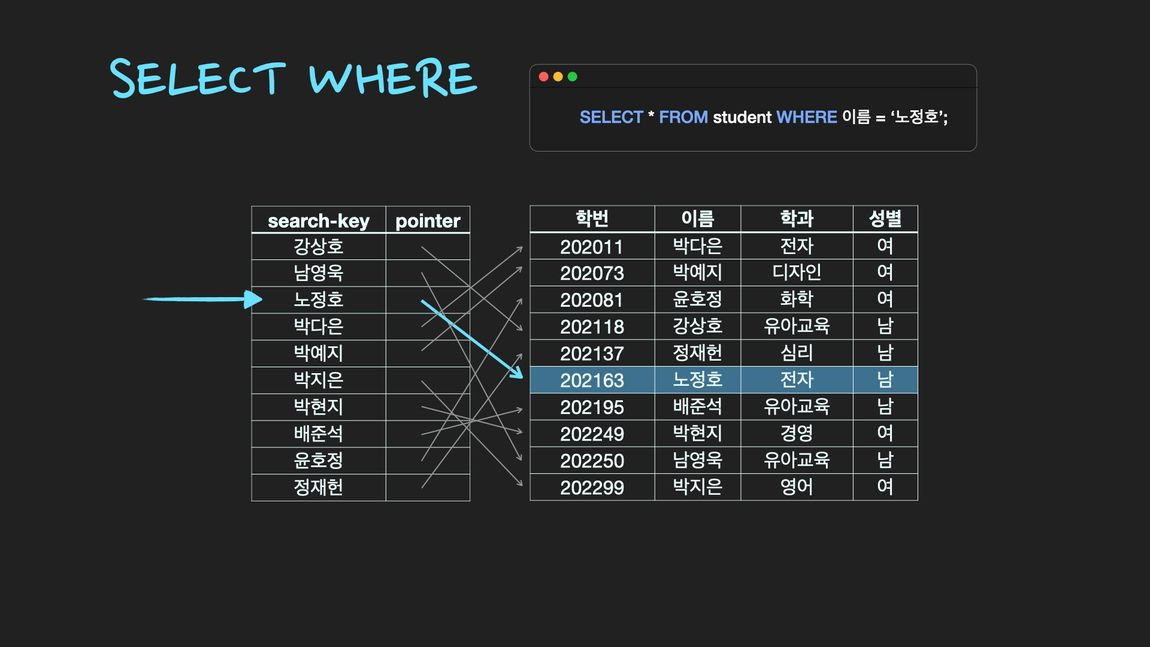
Table에 데이터를 지속적으로 저장하게 되면 내부적으로 순서 없이 쌓이게 된다. 이 경우에 특정 조건을 만족하는 데이터를 찾고자 WHERE절을 사용한다. Table의 row(record)를 처음부터 끝까지 모두 접근하여 검색조건과 일치하는지 비교하는 과정이 필요한데, 이를 Full Table Scan이라고 한다. 하지만 특정 coloumn에 대한 Index를 생성해 놓은 경우 해당 속성에 대하여 search-key가 정렬되어 저장되어 있기 때문에 조건 검색(SELECT ~ WHERE) 속도가 굉장히 빠르다.
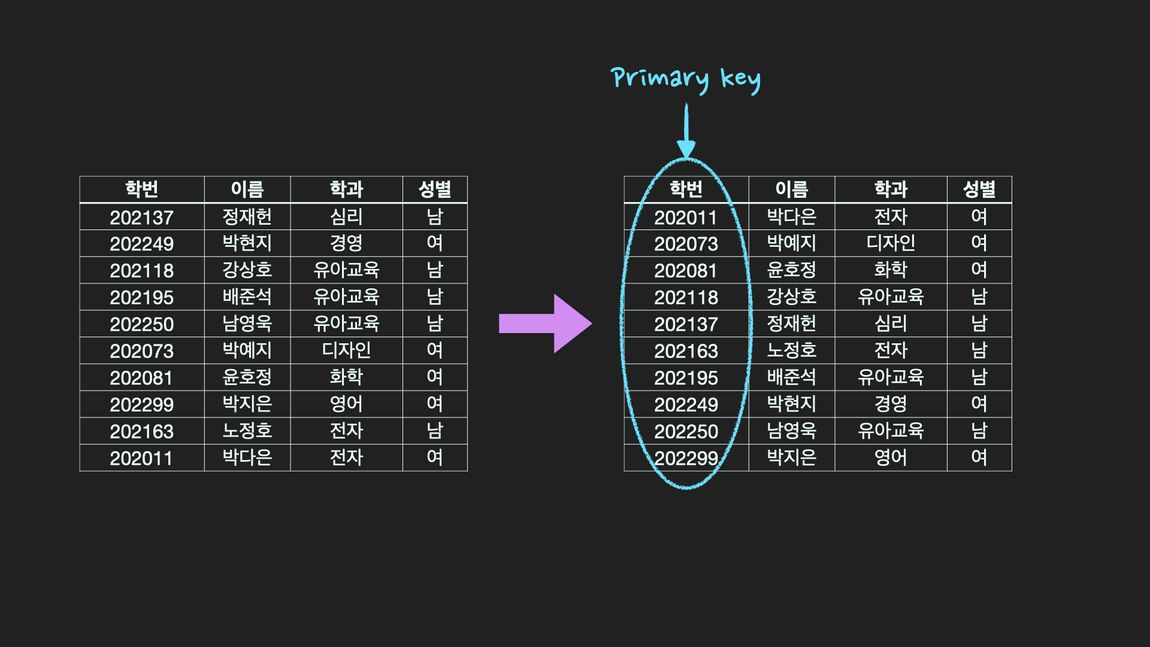
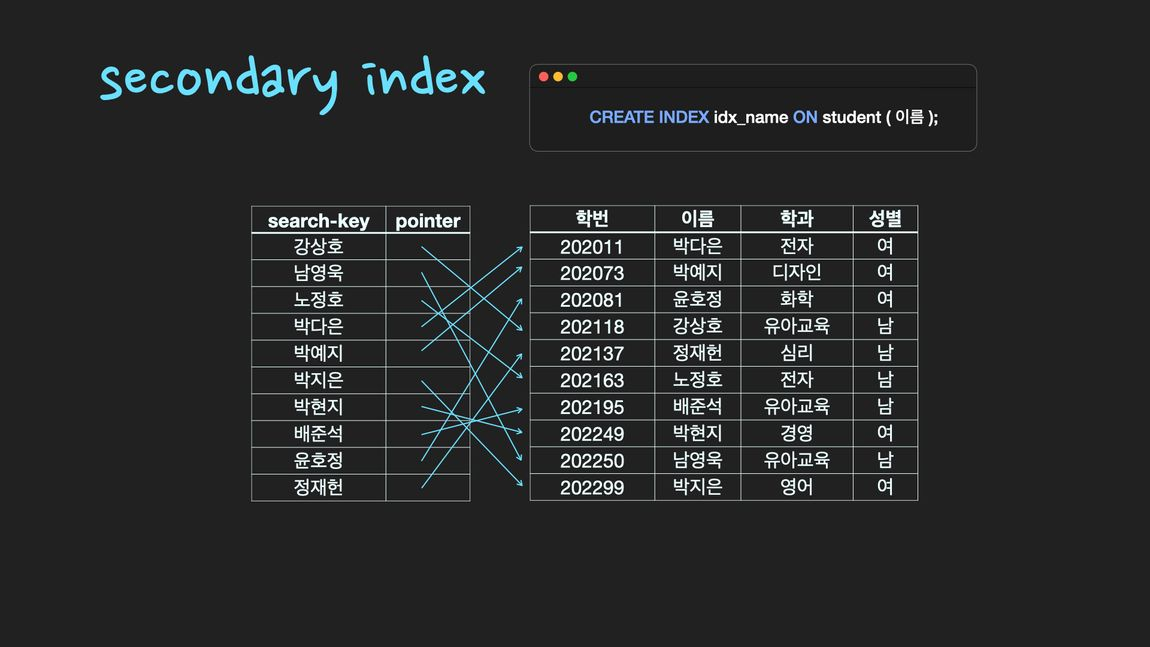
클러스터형 인덱스와 보조 인덱스(clustering index & secondary index)
- clustering index: 특정 column을 기본키(primary key)로 지정하면 자동으로 클러스터형 인덱스가 생성되고, 해당 column 기준으로 정렬이 된다. Table 자체가 정렬된 하나의 index. 마치 영어사전처럼 책의 내용 자체가 정렬된 것을 떠올리면 쉽다.
- secondary index : 일반 책의 찾아보기와 같이 별도의 공간에 인덱스가 생성된다.
create index와 같이 index를 생성하기를 하거나 고유키(unique key)로 지정하면 보조 인덱스가 생성된다.
Index의 장단점
Index의 최대 장점은 검색 속도 향상 (SELECT~WHERE~ ).
테이블을 만들고 안에 데이터가 쌓이게 되면 테이블의 record는 내부적으로 순서가 없이 뒤죽박죽으로 저장된다.
이렇게 되면 WHERE절을 통해 특정 조건에 맞는 데이터들을 찾아낼 때에도 reocrd의 처음부터 끝까지 다 읽어서 검색 조건과 맞는지 비교해야 함.
이것을 Full Table Scan이라고 한다. 반면에 index를 생성하면 index에는 데이터들이 정렬되어 저장되어 있기 때문에 검색 조건에 일치하는 데이터들을 빠르게 찾아낼 수 있다. 이것이 Index를 사용하는 가장 큰 이유.
Index의 단점으로는 크게 두 가지.
-
추가 저장공간 필요
index를 생성하면 index 자료구조를 위한 저장 공간이 추가적으로 필요요. 보통 table의 크기의 10%정도의 공간을 차지
-
느린 데이터 변경 작업
검색이 아닌 데이터 변경을 할 때, 즉 INSERT, UPDATE, DELETE가 자주 발생하면 성능이 나빠질 수 있다. 그 이유는 보통 B+tree구조의 index는 데이터가 추가 삭제 될 때마다 tree의 구조가 변경될 수 있기 때문. 즉 인덱스의 재구성이 필요하기 때문에 추가적인 자원이 소모.
⭐⭐⭐⭐ index를 어느 column에 사용하는 것이 좋을까?
index는 where 절에서 자주 조회되고, 수정 빈도가 낮으며, 카디널리티는 높고, 선택도가 낮은 column을 선택해서 설정하는 것이 가장 좋다.
| 기준 | 적합성 |
|---|---|
| 카디널리티(Cardinality) | 높을수록 적합 (데이터 중복이 적을수록 적합) |
| 선택도(Selectivity) | 낮을수록 적합 |
| 조회 활용도 | 높을수록 적합 (where 절에서 많이 사용되면 적합) |
| 수정 빈도 | 낮을수록 적합 |
Index 효과적으로 사용하는 방법
- SELECT WHERE절에 자주 사용되는 Column에 대해 index를 생성하는 것이 좋다.
- 데이터 수정 빈도가 낮을수록 적합. insert / update / delete 작업 시, 데이터에 변화가 생기기 때문에 index에서는 매번 정렬을 다시 해야한다. 이에 따른 부하가 발생하기 때문에 수정 빈도가 낮은 column을 index로 설정하면 좋다.
- 데이터의 중복이 높은 column은 index 효과가 별로 없다. 예를 들어 성별은 종류가 2 가지 밖에 없으므로 index를 생성하지 않는 것이 좋다. 즉, 선택도가 낮을 때 유리.(보통 5~10% 이내)
- 데이터의 양이 많을 수록 index로 인한 성능향상이 더 크다. 데이터 양이 적다면 index의 혜택보단 손해가 더 클 수 있다.
- Join 조건으로 자주 사용되는 column의 경우
- 한 table에 index가 너무 많은면 데이터 수정시 소요되는 시간이 너무 길어질 수 있다. (table당 4~5개 정도 권장)
데이터를 검색을 할 때 hash table의 시간복잡도는 O(1)이고 b+tree는 O(logn)으로 더 느린데 왜 index는 hash table이 아니라 b+tree로 구현?
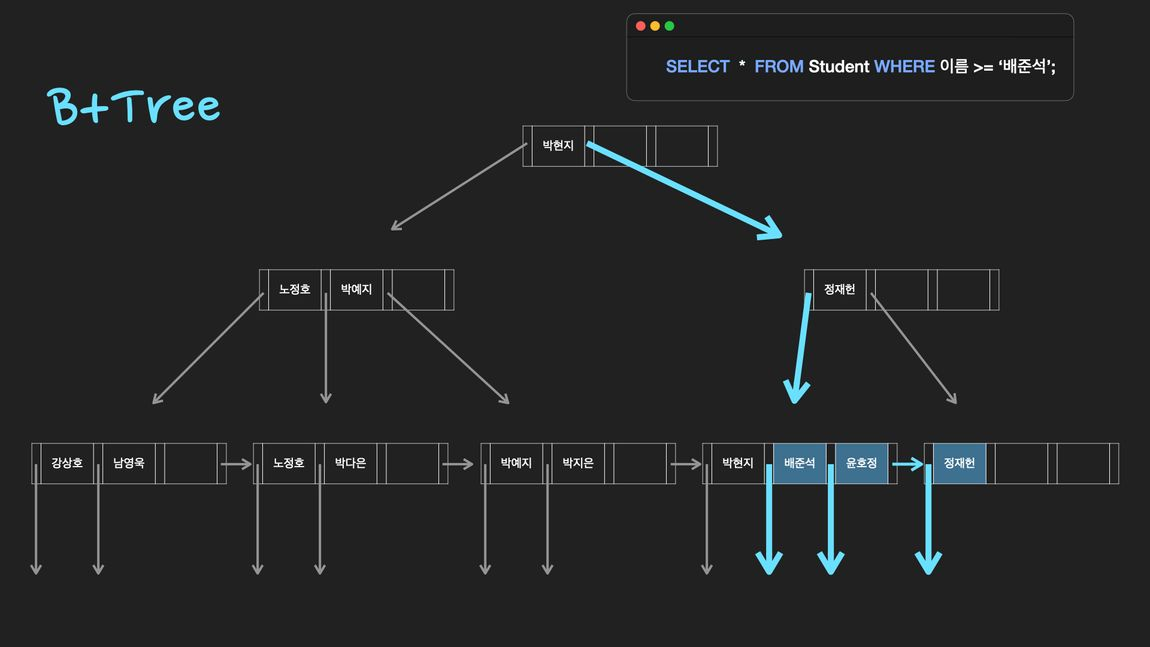
Hash table을 사용하면 하나의 데이터를 탐색하는 시간은 O(1)로 b+tree보다 빠르지만, 값이 정렬되어 있지 않기 때문에 부등호를 사용하는 query에 대해서는 매우 비효율적이게 되어 데이터를 정렬해서 저장하는 b+tree를 이용
Hash index
hash index는 빠른 데이터 검색$O(1)$이 필요할 때 유용하다. 하지만 index로써 hash index가 사용되는 경우는 제한적.
왜냐하면 hash index는 등호(=) 연산에만 특화되었기 때문이다. 데이터가 조금이라도 달라지면 hash funcdtion은 완전히 다른 hash 값을 생성하는데, 이러한 특성 때문에 부등호 연산(>, <)이 자주 사용되는 DB 검색에는 hash index가 적합하지 않다.
참조 : 개발남노씨 운영체제
Leave a comment