
[Database] DB 구조 & 설계
DB 구조 & 설계
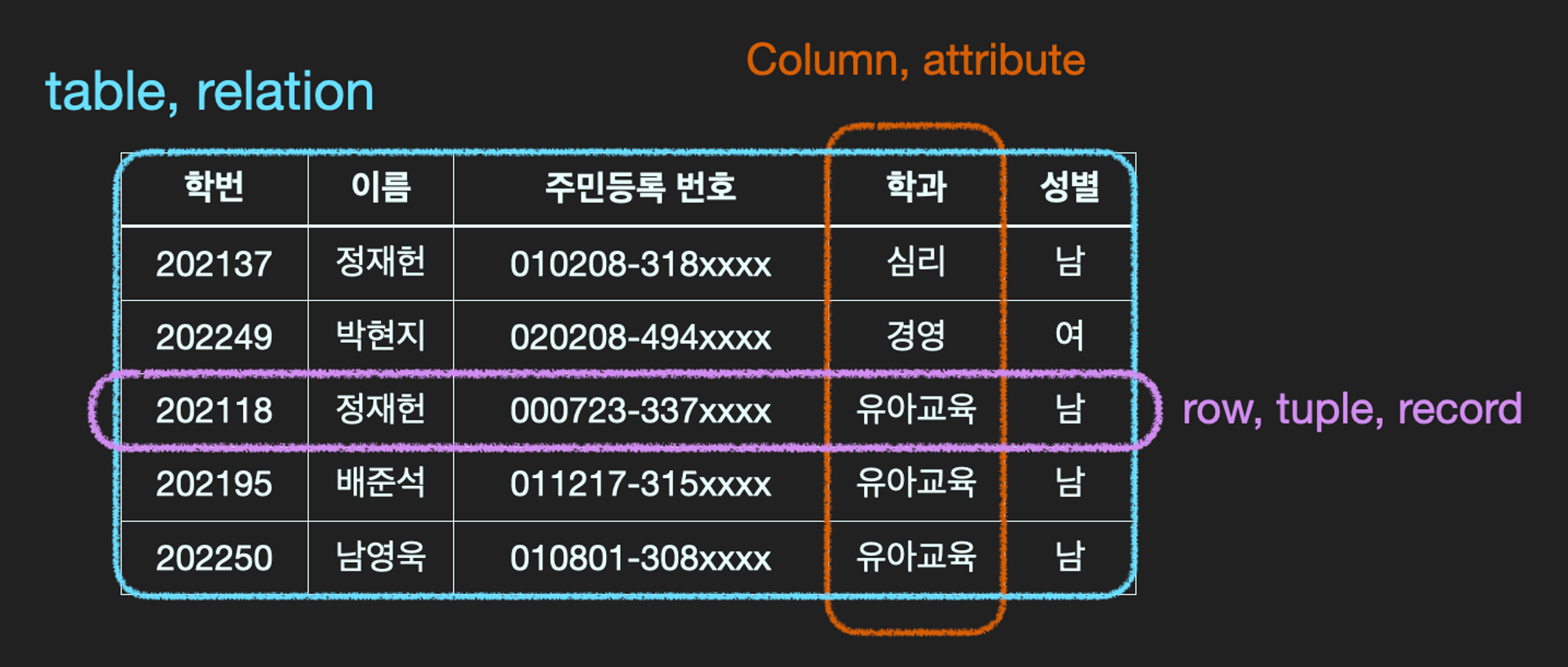
Primary key란?
candidate key 중 선택한 main key로써, 각 row를 unique하게 구분하는 column(또는 column의 집합)을 말한다. 그래서 기본키는 Null 값을 가질 수 없고, 중복된 값을 가질 수 없다.
Relation
table 중 데이터베이스에서 사용되기 위한 조건을 갖춘 것이 relation
Relation의 제약 조건 중 가장 자주 등장하는 조건.
- table의 cell은 단일 값을 갖는다.
- 어떤 두 개의 row도 동일하지 않다.
하지만 통상적으로 relation과 table이란 용어를 구분하지 않고 사용하기도 한다.
Primary key
Super Key(슈퍼키)는 각 row를 유일하게 식별할 수 있는 하나 또는 그 이상의 속성들의 집합 슈퍼키는 유일성만 만족하면 슈퍼키가 될 수 있다.
- 유일성 : 하나의 key 값으로 특정 row만을 유일하게 찾아낼 수 있어야 한다.
- 예시
- (학번)
- (학번,이름)
- (학번, 이름, 학과)
- (주민등록번호)
- (주민등록번호, 학과, 성별)
- 등등
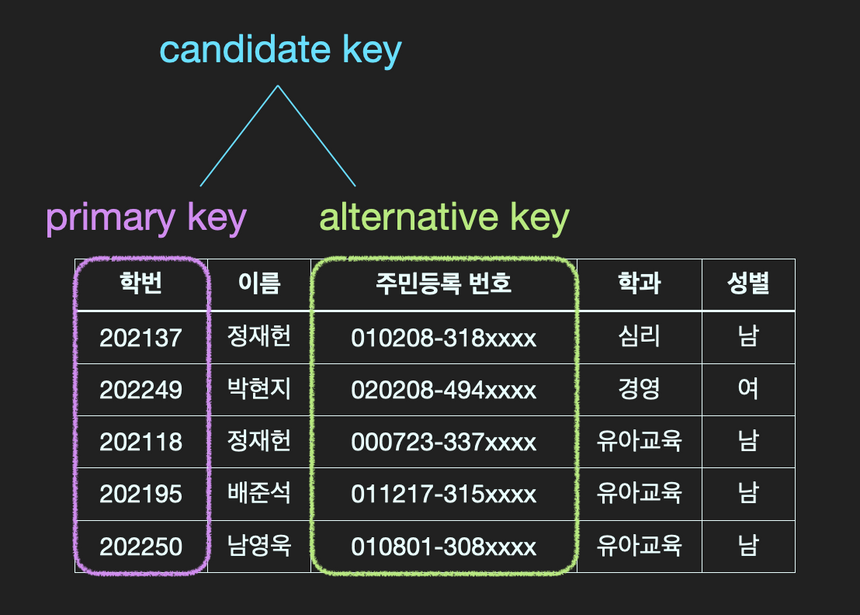
Candidate key(후보키)는 Super key 중에서 더이상 쪼개질 수 없는 Superkey를 Candidate Key라고 한다. 즉 각 row를 유일하게 식별할 수 있는 최소한의 속성들의 집합.
- 최소성 : 모든 row를 유일하게 식별하는데 꼭 필요한 속성만으로 구성되어야 한다.
- 예시
- (학번)
- (주민등록번호)
Primary key(기본키)는 candidate key 중 선택한 main key로써, 각 row를 구분하는 유일한 열을 말한다. 그래서 기본키는 Null 값을 가질 수 없고, 중복된 값을 가질 수 없다. 기본키는 table당 1개만 지정해야 함.
Alternative key(대체키) 는 후보키가 두 개 이상일 경우, 기본키로 지정이 되지 못하고 남은 후보키를 말한다.
관계형 데이터베이스의 N:M 관계란?
관계형 데이터베이스에서 양쪽 entity 모두가 서로에게 1:N 관계를 갖는 구조
1:N
관계형 데이터베이스에서 하나의 entity(table)가 관계를 맺은 entity의 여러 객체를 가질 수 있는 구조를 말한다.
두 table간의 관계를 mapping cardinality로 표현하고, 종류는 크게 다음과 같다
- 1:1
- 1:N
- N:M
예시) 실무에서 가장 자주 등장하는 1:N 구조인 고객-주문 관계
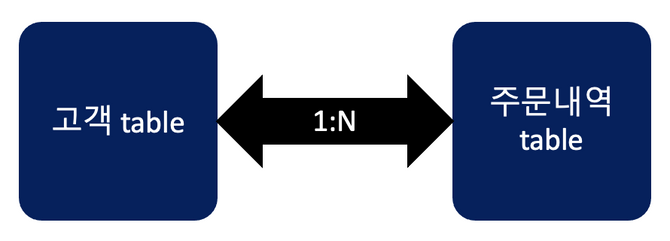
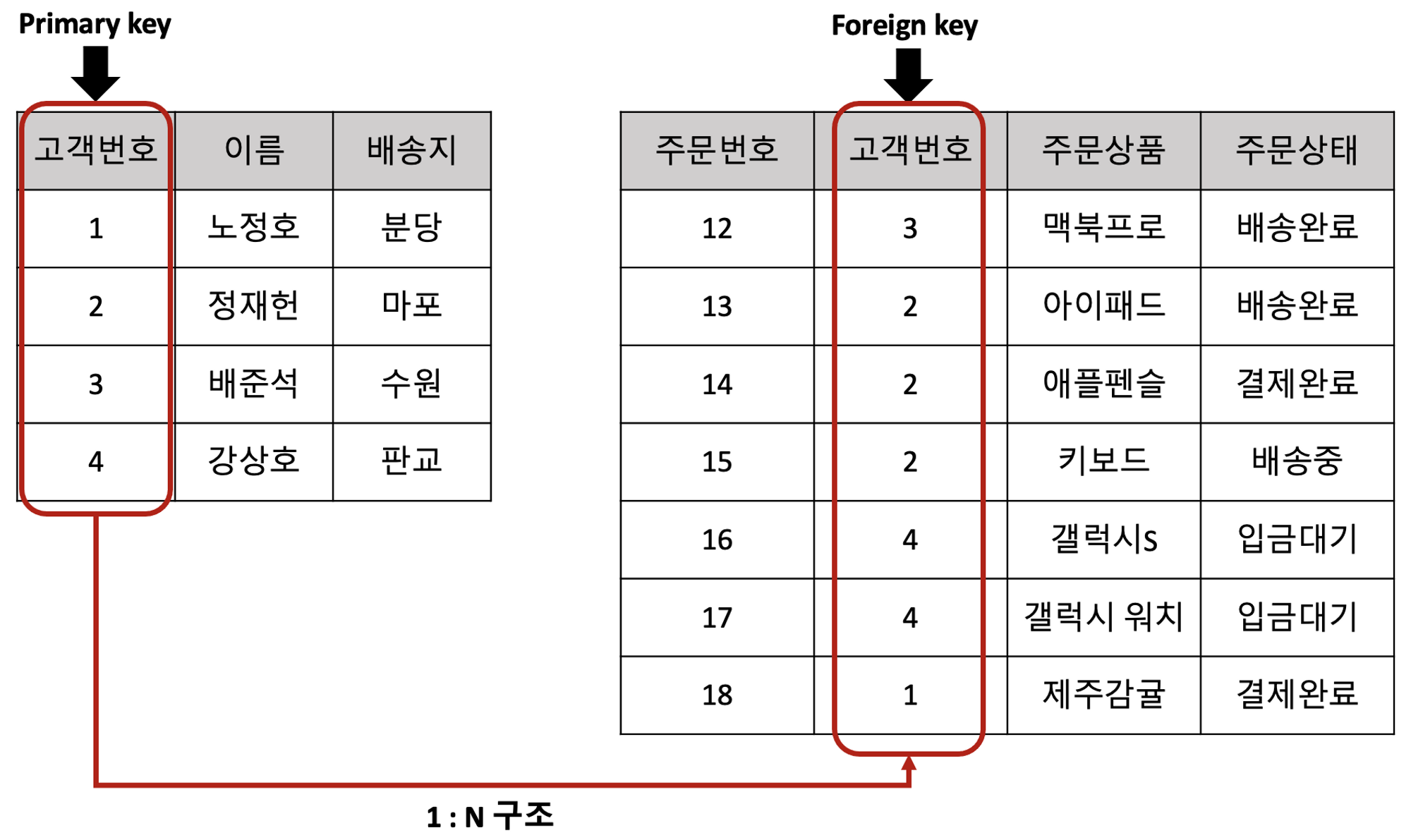
1:N 구조에서는 보통 primary key - foreign key를 사용하여 관계를 맺습니다.
Foreign key(외래키)는 다른 table의 Primary key column과 연결되는(참조되는) table의 column을 의미한다. 즉, 두 table을 연결할 때 한 table의 외래키가 다른 하나의 table의 기본키.
그림의 예시와 같은 상황에서 고객의 정보가 변경된다고 해도, 주문내역 table은 수정할 필요가 전혀 없게 되어 효율적인 데이터베이스 운영이 가능
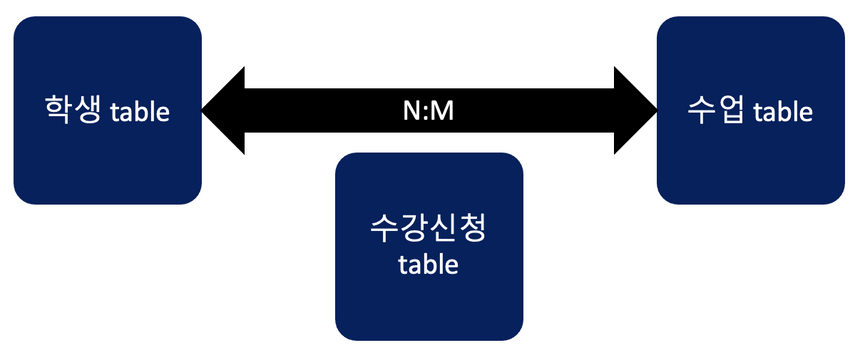
N:M 관계
관계형 데이터베이스에서 양쪽 entity 모두가 서로에게 1:N 관계를 갖는 구조
N:M 구조에서는 보통 새로운 table(Mapping table)을 통해서 관계.
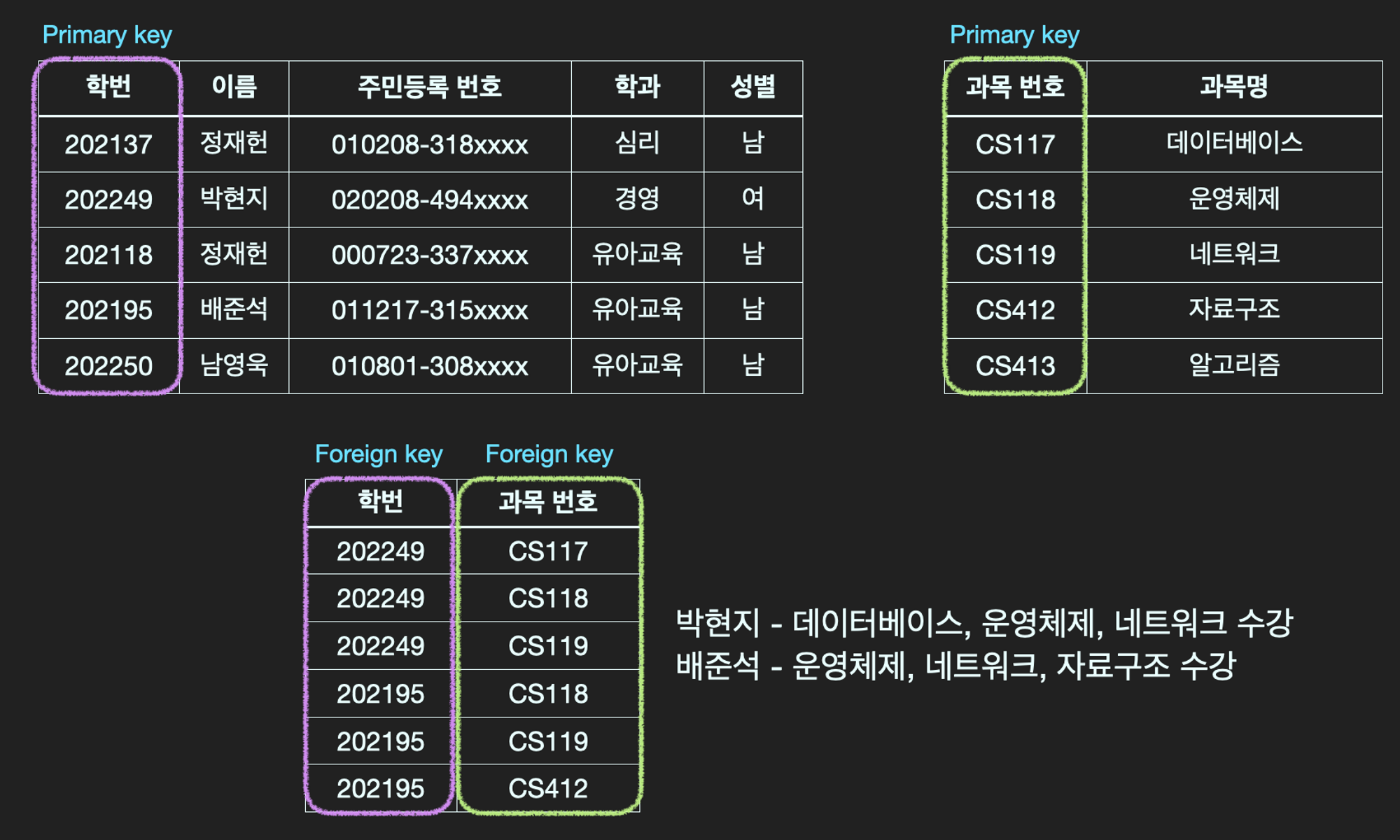
예시) 가장 친숙한 N:M 구조인 학생-수업 관계
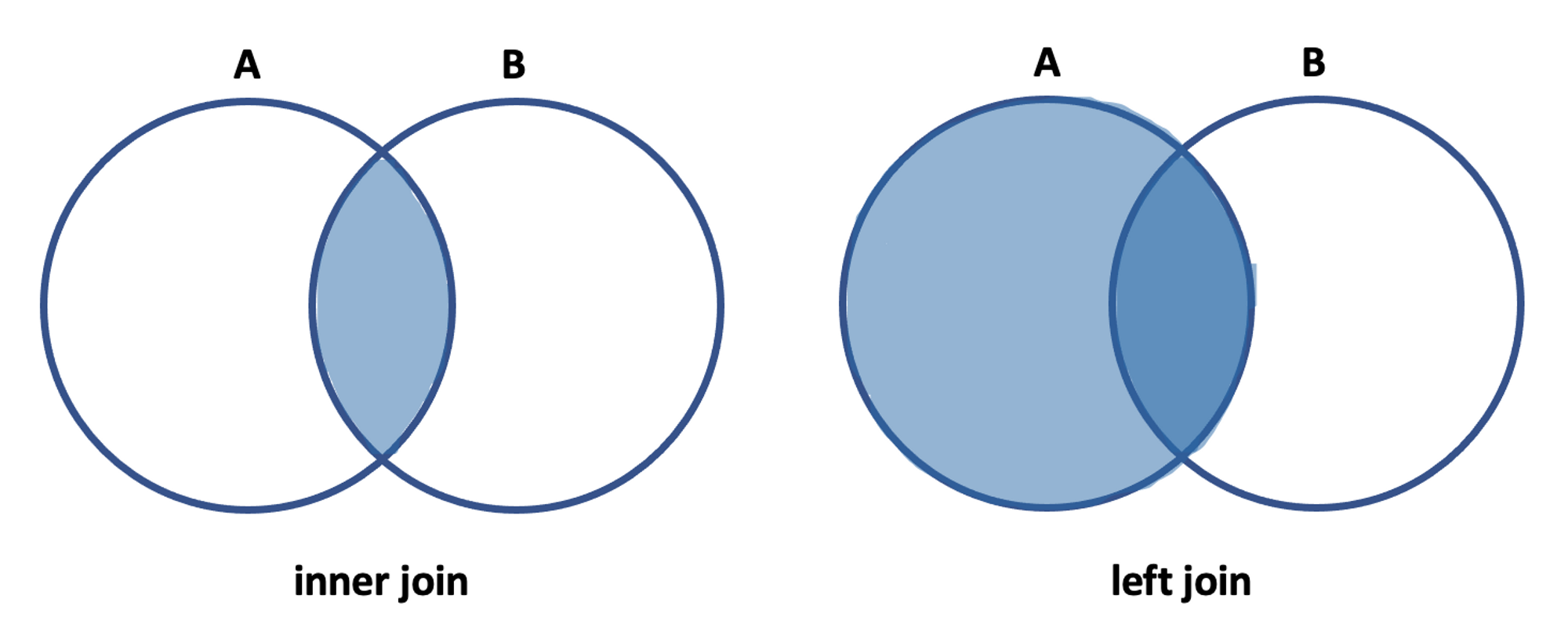
left outer join, inner join 차이
Join이란 두 개 이상의 테이블을 서로 연결하여 하나의 결과를 만들어 보여주는 것을 말한다. inner join(또는 join)은 두 테이블에 모두 있는 내용만 join되는 방식 left outer join(또는 left join)은 왼쪽 table의 모든 행에 대해서 join을 진행한다.
Inner Join(내부조인)
- 두 테이블을 연결할 때 가장 많이 사용되는 것이 inner join
- inner join은 줄여서 join으로 칭하기도 한다.
- 두 테이블을 join하기 위해서는 두 테이블이 1:N 관계로 연결되어야 함.
- 1:N 관계는 주로 primary key와 foreign key 관계로 맺어져 있음. (상호조인의 경우에는 PK-FK 관계가 아니여도 됌)
[SQL JOIN 예시]
- vedio table
| id | title | y_id |
|---|---|---|
| 1 | 데이터베이스 완전정복 | 2 |
| 2 | 볼리비아 광산 탐방기 | 4 |
| 3 | 침vs펄 토론 | 3 |
| 4 | 운영체제 완전 정복 | 2 |
| 5 | 충격실화 대한민국이 해냈다 | Null |
- youtuber table
| id | name | 채널 설명 |
|---|---|---|
| 1 | 쯔양 | 먹방 |
| 2 | 개발남노씨 | 개발 |
| 3 | 침착맨 | 예능 |
| 4 | 빠니보틀 | 여행 |
select * from vedio inner join youtuber on vedio.y_id = youtuber.id;
- inner join의 sql query 예시
| id | title | y_id | name | 채널 설명 |
|---|---|---|---|---|
| 1 | 데이터베이스 완전정복 | 2 | 개발남노씨 | 개발 |
| 2 | 볼리비아 광산 탐방기 | 4 | 빠니보틀 | 여행 |
| 3 | 침vs펄 토론 | 3 | 침착맨 | 예능 |
| 4 | 운영체제 완전 정복 | 2 | 개발남노씨 | 개발 |
두 table에 공통된 데이터가 존재하는 행에 대해서만 데이터를 검색
left outer join(외부조인)
select * from vedio left join youtuber on vedio.y_id = youtuber.id;
- left outer join 예시
| id | title | y_id | name | 채널 설명 |
|---|---|---|---|---|
| 1 | 데이터베이스 완전정복 | 2 | 개발남노씨 | 개발 |
| 2 | 볼리비아 광산 탐방기 | 4 | 빠니보틀 | 여행 |
| 3 | 침vs펄 토론 | 3 | 침착맨 | 예능 |
| 4 | 운영체제 완전 정복 | 2 | 개발남노씨 | 개발 |
| 5 | 충격실화 대한민국이 해냈다 | Null | Null | Null |
왼쪽 vedio table의 모든 데이터를 포함한 데이터를 검색
⭐ RDB - NoSQL를 비교 설명
- 관계형 데이터베이스(RDB)는 사전에 엄격하게 정의된 DB schema를 요구하는 table 기반 데이터 구조를 갖는다.
- NoSQL(비관계형 데이터베이스)은 table 형식이 아닌 비정형 데이터를 저장할 수 있도록 지원.
- RDB는 엄격한 schema로 인해 데이터 중복이 없기 때문에 데이터 update가 많을 때 유리
- NoSQL의 경우 데이터 중복으로 인해 데이터 update 시 모든 컬렉션에서 수정이 필요하기 때문에 update가 적고 조회가 많을 때 유리
Key-value storage system ( NoSQL )
기존의 관계형 database의 경우에는 단일 기업의 데이터를 다루는데 최적화 되어 있다. 하지만 최신 데이터들은 꼭 관계형으로 처리될 필요가 없는 경우도 많고, 다뤄야 하는 데이터의 양도 훨씬 커져, 즉 Big data라고 일컬어 지는 많은 양의 데이터를를 처리하기 위한 방법으로 다양한 해결책이 나왔는데, 그 중 하나의 방법이 Key-value storage system이 있다.
Key-value stores는 NoSQL system이라고도 불린다. 그 이유는 SQL을 보통 지원하지 않고 transaction을 지원하지 않는 등 SQL을 사용하는 기존의 RDB와의 차이점 때문이다.
MongoDB
db.createCollection("student")
db.student.insert({"id": 2022394, "name": "Nossi", "class": ["Math", "Eng"]})
db.student.insert({"id": 2021921, "name": "Bob", "class": ["Eng"]})
db.student.find() // Fetch all students in JSON format
db.student.findOne({"id": 2022394}) // Find one matching student
db.student.remove({"name": "Nossi"}) // Delete matching students
db.student.drop() // Drops the entire collection
RDB vs NoSQL
| RDB (SQL) | NoSQL | |
|---|---|---|
| 데이터 저장 모델 | table | json document / key-value / 그래프 등 |
| 개발 목적 | 데이터 중복 감소 | 애자일 / 확장가능성 / 수정가능성 |
| 예시 | Oracle, MySQL, PostgreSQL 등 | MongoDB, DynamoDB 등 |
| Schema | 엄격한 데이터 구조 | 유연한 데이터 구조 |
| ⭐장점 | 명확한 데이터구조 보장, 데이터 중복 없이 한 번만 저장 (무결성), 데이터 중복이 없어서 데이터 update 용이 | 유연하고 자유로운 데이터 구조, 새로운 필드 추가 자유로움, 수평적 확장(scale out) 용이 |
| ⭐단점 | 시스템이 커지면 Join문이 많은 복잡한 query가 필요, 수평적 확장이 까다로워 비용이 큰 수직적 확장(Scale up)이 주로 사용됌, 데이터 구조가 유연하지 못함 | 데이터 중복 발생 가능, 중복 데이터가 많기 때문에 데이터 변경 시 모든 컬렉션에서 수정이 필요함, 명확한 데이터구조 보장 X |
| ⭐사용 | 데이터 구조가 변경될 여지가 없이 명확한 경우, 데이터 update가 잦은 시스템 (중복 데이터가 없으므로 변경에 유리) | 정확한 데이터 구조가 정해지지 않은 경우, Update가 자주 이루어지지 않는 경우 (조회가 많은 경우), 데이터 양이 매우 많은 경우 (scale out 가능) |
수직적 확장Scale-up vs 수평적 확장 Scale-out
- DB와 비교하여 NoSQL의 특징은 ACID, Transaction을 지원하지 않음. - RDB는 ACID와 Transaction을 보장하기 위해 수평적 확장이 쉽지가 않음.
-
RDB 같은 경우에는 multiple server로 수평적 확장을 하게 되면 join을 하기 위해 굉장히 복잡한 과정이 필요함
- RDB도 수평적 확장이 가능하지만 NoSQL에 비해 훨씬 복잡함.
- RDB를 수평적 확장하려면 샤딩(sharding)(데이터가 수평적으로 분할되고 기기의 모음 전반에 걸쳐 분산되는 경우)이 필요함.
- ACID 준수를 유지하면서 RDB를 샤딩하는 것은 매우 까다로운 작업.
참조 : 개발남노씨 운영체제
Leave a comment